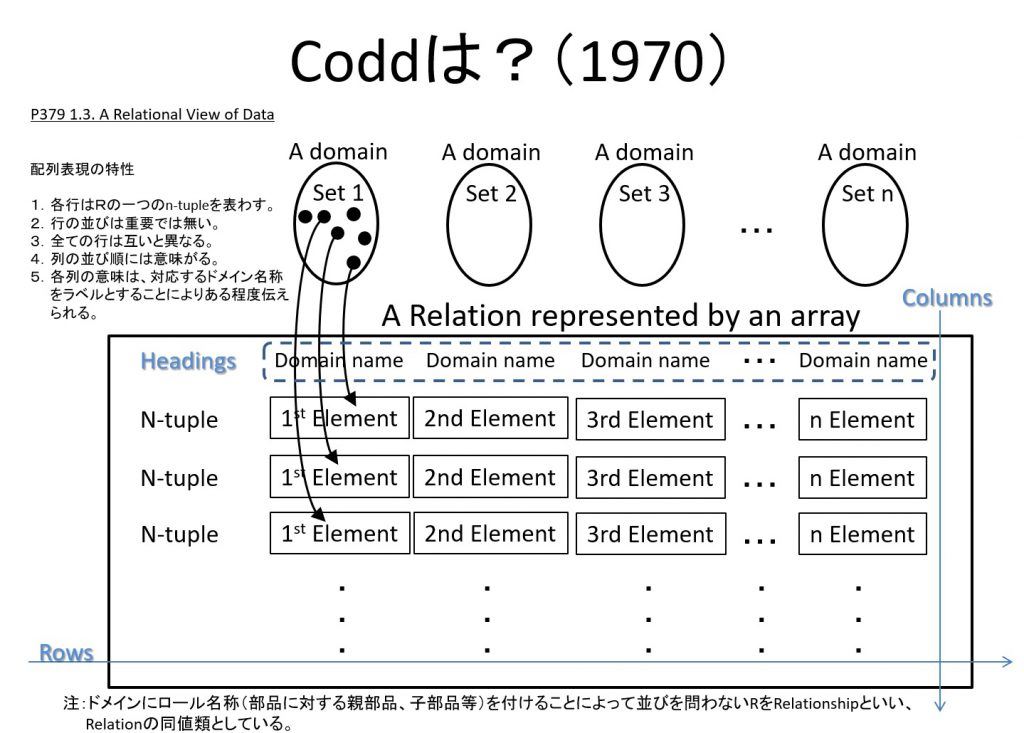
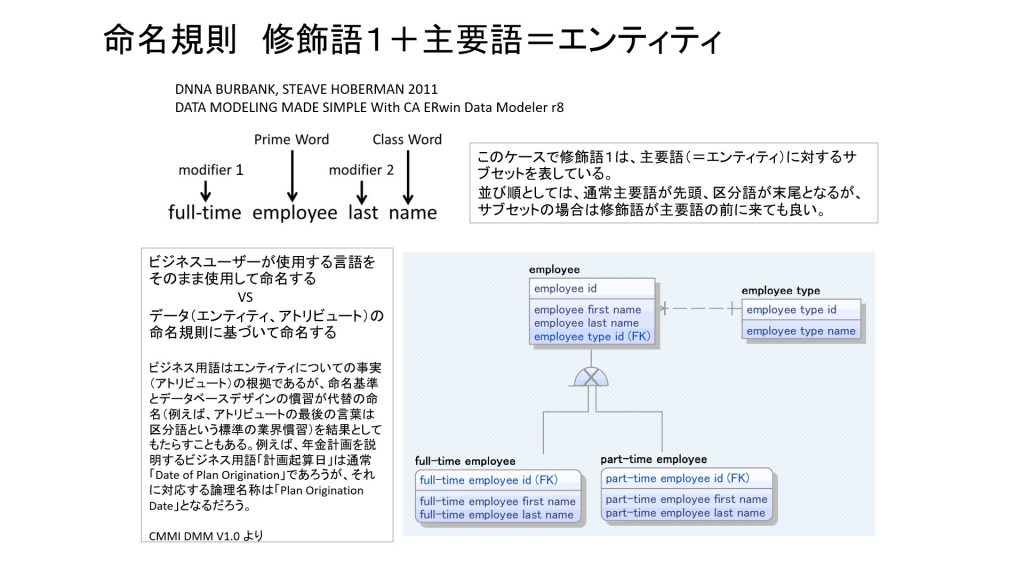
10月21日(木)に開催された月次の第10分科会で話題となった「統制語彙」とデータモデルの果たす役割に関するディスカッションを取り掛かりに、今回のブログ題材として取上げる。
この回の勉強会では、4月迄に行われた第12分科会話題とDMBoK2第9章「ドキュメントとコンテンツ管理」記述内容を材料にする形で、分科会メンバ國澤氏からの話題説明および考え方を解説する形で議論が進められた(題目:「統制語彙とデータモデル」、分科会参加者14名、ZOOMオンライン方式)。
今回の話題は、概念データモデリングのアプローチが「統制語彙」(Controlled Vocabularies)を整備するために役に立つというDMBoK2の説明要素を、議論の糸口として始められた。また、同時に統制語彙を取り囲む語彙集合の位置付けとしてフォークソノミ周辺語彙を関係付けた説明があった。単にER図だけでなく用語定義等の説明情報を含めてこその本来の「データモデル」であることも話題要素となった。尚、DMBoK2第5章における概念データモデル・アプローチの基本的考え方は、エンティティ定義と意味の明確化をモデル作成上の主要要素としている点を確認しておくと議論として分かり易い。
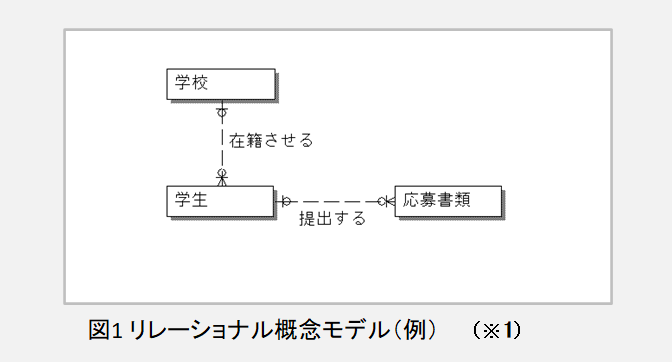
ここで確認のためにDMBoK2(日本語版)p.173での概念モデルの説明を引用する。「概念データモデルには、関連する概念の集合体としてデータ要件の概念が取り込まれる。ここには、特定の領域や業務機能に関する基本的で重要なビジネスエンティティのみが含まれ、各エンティティの説明とエンティティ間のリレーションシップが含まれる」とある。IE表記法を用いたリレーショナル概念データモデルの例として、学校、学生、応募書類の関係をモデル化した例をこの回でも議論題材として取上げた(図1)。
図1に表される動詞句表記が必須であるかどうかについては、モデラーの立場による議論の余地があるものの、このような概念モデルを関係者間で確認し作成する中で、出現する語彙(主にエンティティ名となる語彙等)の表す意味合いが共有・図式化され、統制語彙(の候補)として用語整理する上でモデリングの役割が発揮されるという流れである。更に、この概念モデルの表す意味関係を変えずにエンティティの主キー属性を検討し、他の属性項目を加えてゆくことで次段階としての論理データモデルに落とし込むのがデータモデル詳細化の進め方となる(DMBoK2 日本語版、p.175、図48参照)。その実装に向けたモデル整備過程ではリレーショナルモデルの正規化といった要素の考慮等が必要とされるが、ここでは語彙論議から外れるためその詳細は割愛する。
当日の議論には出ていないが、筆者の立場としては、このような手続きにより統制語彙候補を抽出した後で、最終的に統制語彙としての採用要否の検討要素として、オントロジの考え方が必要になるという点をここで加えておきたい。例えば、図1の例では、「学生」という語はオントロジ視点を通せば「ロール」概念として位置付くものであり、論理モデル化でのモデル表現の仕方に影響が出ることになる(いわゆる海外で取上げられることの多いパーティモデルは、この視点での立場を取っている)。更に、用語を利用する部門によっては、同じ用語の意味使いに差異が生まれることが実務上存在する点を考慮する際には、統制語彙レイヤ(≑共通語彙)と部門用語レイヤ(部門ビューともいえる)のような階層化視点での用語整理実施という語彙設計も必要であろう。これは語彙の方言、いわば多元的フォークソノミの話題として深掘り検討すべき内容と考えられる。
DMBoK2第9章では、統制語彙の実用的な例として図書館情報分野で利用されるダブリンコア(Dublin Core)の語彙が紹介されている。日本でのこの語彙の利用状況は、国立国会図書館のダブリンコアメタデータ記述(DC-NDL)Webページで知ることができる(こちらを参照 )。
統制語彙の考え方に関連した第二の話題としてここで次の補足をしたい。IPA(情報処理推進機構)の推進するIMI情報共有基盤事業(Infrastructure for Multilayer
Interoperability)について簡単に触れる。これは、電子行政分野におけるオープンな利用環境整備に向けたアクションプランの一環で、データに用いる文字や用語を共通化し、情報の共有や活用を円滑に行うための基盤構築プロジェクトとして2013年を起点として計画・推進されている(※2)。これは、共通語彙基盤および文字情報基盤の2要素からなり、この中の共通語彙基盤の内容が今回の話題に関係する話題として参照できる。
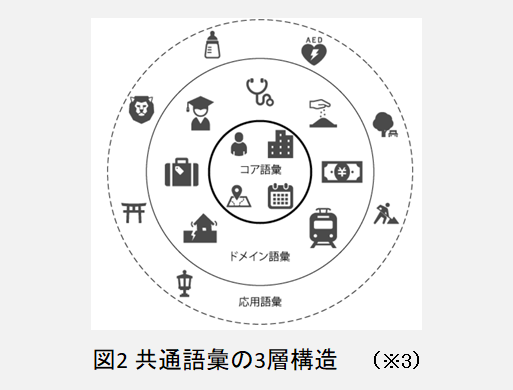
このプロジェクトでは、行政分野でのデータ流通相互運用性向上を目指す中で、コア語彙およびドメイン語彙からなる語彙データベース(DB)構築が取組まれている。分科会で議論した概念データモデル作成のアプローチとは異なる方式で共通語彙の整備が行われ、2019年2月時点でコア語彙バージョン2.4.2が公開され(現時点最新)、ここでの共通語彙群の位置付けは、図2のように表現されている。
この図2での語彙階層は、以下のように説明されている。
(1)コア語彙: 分野を超えて使われる共通性のある用語(【人】【氏名】など)の集合
(2)ドメイン語彙: コア語彙の概念を継承して定義した、分野固有の用語の集合
(3)応用語彙: 現場の必要に応じ,既存の語彙を継承した独自の 語彙を定義する必要が出てくるが,これを応用語彙と呼ぶ。応用語彙は,将来,分野に共通な語彙を洗い出すなどによりドメイン
語彙へと整理されていくことを想定している。
IMI共通語彙基盤の中で定義する語彙範囲は(1)と(2)であり、現時点コア語彙(1)のうちクラス語彙約60、プロパティ語彙約250が定義されている。(2)は今後の応用分野の開発の中で(3)と共に定義してゆく領域として扱われるものと説明され、プロジェクトWebページでは現在(1)項目の共通語彙が定義公開されている。
概念モデルアプローチから抽出されるのは主にエンティティ名に関する語彙(用語)になり得ることは冒頭からの議論紹介の中で記述したが、こちらのアプローチでは、クラス語(ほぼエンティティに対応)に加えてプロパティ語(リレーショナルモデルでは属性項目に相当)が定義されている点に違いがある。これはLOD(Linked Open Data)トリブル表現からの設計アプローチでは、エンティティ(≑クラス)、属性(≑プロパティ)、インスタンス/オカレンスが区別されない形となる集合的用語認識から始まる結果、当然現れる現象といえる。このようなモデルでオントロジ言語利用(OWL:Web Ontology Language)の必要性発生とも関係している。実際、(1)で定義された語彙の実装は、XMLおよびRDF定義形式で提供されている(この語彙定義は、同プロジェクトWebサイトからダウンロードできる)。
ここで見たように、語彙定義、そして相互利用のための共通化を目的として整理する語彙種別や内容範囲に違いが現れるということは、統制語彙や共通語彙という呼び名とその整備アプローチに加えて、語彙定義を行う目的と適用方法および範囲を先だって明確化する必要があることを示唆している。更に、これに加え、複合語、部門用語、方言的使い方を設計上考慮するという点も含むべきであると筆者は考える。この辺りは、DMBoK2 日本語版pp.339-343、「1.3.2.4 用語管理」~「1.3.2.9 オントロジ」の説明内容に着目すると、より分かり易いものとなる。
このようにして整備した語彙群を共有化し、管理実現を可能にするには、参照データ、メタデータとしての管理機能群を提供することが実装の要点となる。これらについてはDMBoK2第10章「参照データとマスタデータ」、第12章「メタデータ管理」の各章に関連する考え方や情報が取上げられており、更なる興味のある方はこれらの章を参考することにしたい。その際、語彙の統制管理(開発過程での利用を含む)とビジネス利用者から見た利用語彙/用語の運営とは区別するものと捉える方が分かりやすいと考える。それは、前者は技術メタデータ用語管理、データディクショナリ管理の領域話題として扱われ、後者はグローサリー(用語辞書、ビジネス用語集、メタデータ管理の一部)の提供話題として分けて説明される傾向が高いからである。これはまた、メタモデルの作成方針とも関係する。参考に、データディクショナリとビジネス用語を分けて管理するための概念メタモデル図を図3に例示する。
またDMBoK2の上記各章中に記述されているように、語彙/用語の整理および利用検討に当たっては、同音異義語、異音同義語、同意語(シソーラス)、複合語といった見方による整理が必要である。これに加え筆者は、基本語彙の辞書だけでなく、先に述べた利用者ビュー(部門ビュー)階層の設定、用語読み仮名(英文字)の活用といった考慮点を追加することが有効であると考えている。
(以上)
※1 DMBoK2
第5章p.174 「図46 リレーショナル概念モデル」を引用
※2 詳細はIPA/IMIページを参照。 https://imi.go.jp/ (2021年10月27日時点)
※3 出典: 情報処理学会デジタルプラクティス Vol.9 No.1 (Jan. 2018)
IMI共通語彙基盤 p.35 図1 共通語彙の3層構造
※4 以下の資料を参考に筆者作成:
The Joint C3 Information Exchange Data Model, Metamodel
(JC3IEDM Metamodel) V. 3.1.4, Feb. 2012,
Multilateral Interoperability Programme(MIP)
[投稿者]中岡 実(インフオラボ游悠 代表/データマネジメントコンサルタント、ITコーディネータ、PMP、認定心理士)