毎年刊行されている情報通信白書の令和2年版が8月から公開されています。
今回は、その概要について特にデータとの関連を中心に紹介します。
第1部 5Gが促すデジタル変革と新たな日常の構築
第1章 令和時代における基盤としての5G
第2章 5Gがもたらす社会全体のデジタル化
第3章 5G時代を支えるデータ流通とセキュリティ
第4章 5Gのその先へ
(第2部は、基本データと政策動向なので省きます。下記をご覧ください。)
https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/r02/pdf/index.html)
昨年度は、「Society 5.0」がメインテーマでしたが、今年度版は、ご覧の通り5Gを中心にその浸透とデジタル化の進展が並行して説明されています。
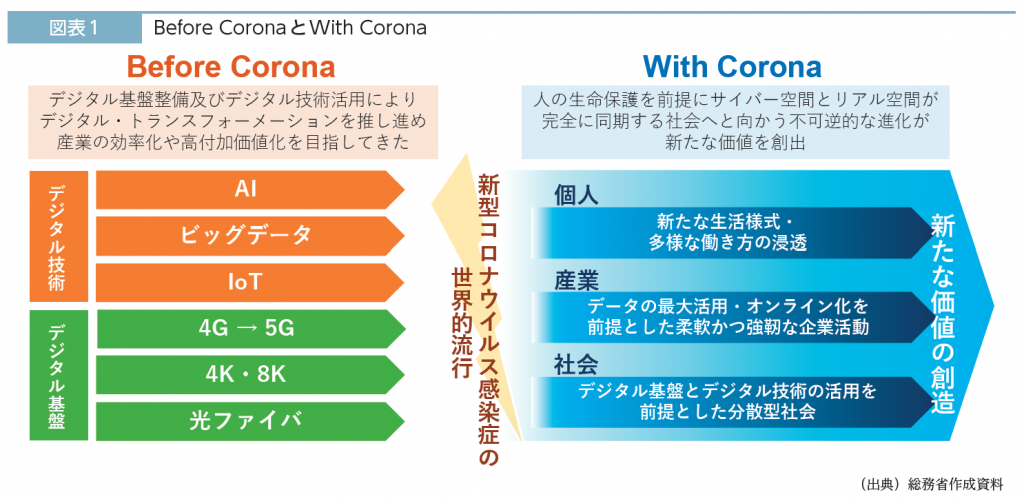
「はじめに」では、今年のCOVID19の感染拡大下でデジタル環境を利用せざるを得ない状況となり否応なくデジタルインフラに移行していく実態が描かれています。
デジタル化が進むのは一見良さそうに見えますが、システム化計画の無い中での局所的なデジタル化によってっ将来的な情報インフラに悪影響を及ぼしかねないことが無ければよいのですが。
第3章は、「5G時代を支えるデータ流通とセキュリティ」と題してデータとの関連で俯瞰しているので覗いてみました。
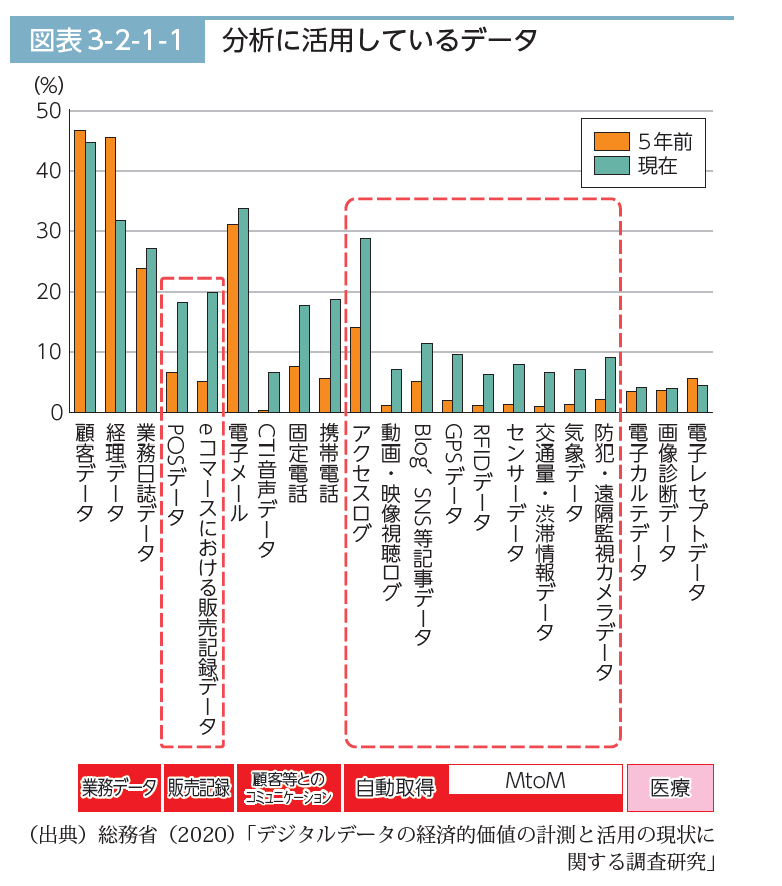
「第2節 デジタルデータ活用の現状と課題」の「1 日本におけるデジタルデータ活用の現状」では、
ア 「データ活用の現状」で、『図表3-2-1-1分析に活用しているデータ』を参照し、『5年前に実施した調査と比較して、POS やeコマースによる販売記録、MtoM データを含む自動取得データの活用が大きく進展しており、各企業におけるIoTの導入が進んでいることがうかがえる』としています。
また、データ活用の割合はやはり中小企業と比べて大企業の方が大きく、データ活用は資本規模の小さい中小企業にとって有利という見方は、そうでもなかったということでしょうか?
イ 「デジタル・トランスフォーメーションの取組」では、『ICT化に関連する業務慣行の改善について尋ねたところ、「社内業務のペーパーレス化」が最も選択された。一方で直近3年以内に実施した取組を尋ねると「テレワーク、Web会議などを活用した柔軟な働き方の促進」が最も多かった。』と記されており、DXの本格的な取り組みはまだこれからというところのようです。
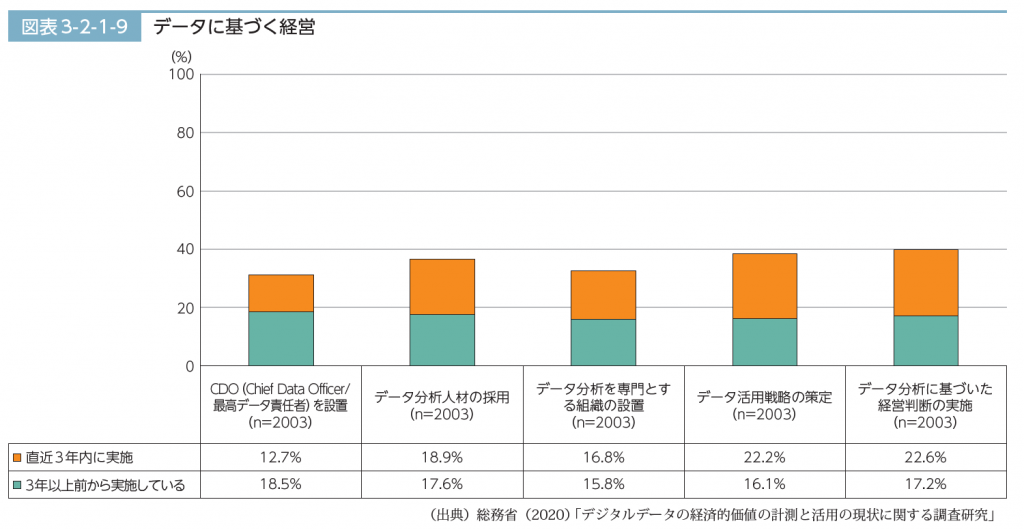
興味深いのは、「データに基づく経営」図でCDOを設置している企業が30%以上もあることです。また、『「データ分析人材の採用」、「データ活用戦略の策定」、「データ分析に基づいた経営判断の実施」を挙げた企業が4割程度あり』、総じて経営戦略・判断にデータを活かしていこうという意識は高まっているようです。
その一方、ウ 『今後のデータ活用の見通し』では、『今後もデータを活用していきたい』という領域が3割程度ある一方で、『今後もデータを活用していく予定はない』、という領域が35.7%~51.4%もある、という結果が出ています。この辺の意識についてはもう少し深く掘り下げてほしいところです。
データ活用という観点では、GAFAといわれるいわゆる情報プラットフォーム企業に大きく市場を奪われている現状で、今後日本企業がどう巻き返していくのか期待したいものです。
本情報通信白書は、日本の情報通信産業の現状を幅広く俯瞰的に捉えたものであり、ハード/通信よりの色合いが強いとも思えますが、日本の情報産業全般を鳥瞰するには良い資料と思えます。既にご覧の方もおられるでしょうが、大部ではありますがご興味があれば一読してみてください。