DAMA日本支部データモデル分科会では、データモデルについてであれば、DMBOKの枠にとらわれずに様々な話題を取り上げて議論・情報共有をしています。今年度は具体的なモデルについて、それぞれの考え方を議論・共有するという取り組みもしています。
さて、このblogではお題をワインとデータモデルとしてみました。ワインは歴史が長いだけあって、バリエーションが非常に多いです。データモデルのちょっとした題材に使えそうです。このモデルの拡張といったお題も、そのうち分科会で取り上げてみるかもしれません。興味を持たれた方はぜひ分科会への参加をご検討ください。DAMA会員であれば、どなたも参加できます。
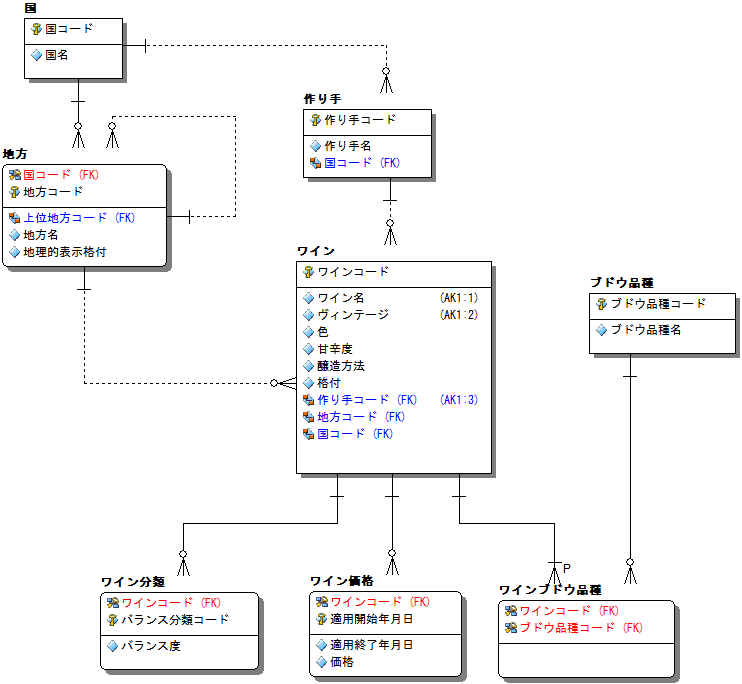
ワインの基本要素としては、ブドウの種類、色(赤、白、ロゼ)、発泡性かどうか、場所といったことになるかと思います。
オールドワールド(フランス、イタリア、スペイン等)は地名(地方、村、畑など)がまず書かれて、ブドウの品種は書かれていなかったりしますが、ニューワールド(カルフォルニア、オーストラリア、チリ等)は、ブドウの品種がまず書かれるパターンがかつては主流でした。

また、オールドワールドでは、複数のぶどう品種を組み合わせることも多いのですが、ニューワールドでは単一品種で勝負したワインが主流です。カルフォルニアワインが有名になったきっかけはカベルネ・ソーヴィニヨンですし、今、コスパの良さで人気のチリカベはチリのカベルネ・ソーヴィニヨンの略語です。

ピノ・ノワールというブドウ品種名が記載されています。 これはフランス、ブルゴーニュ原産です。
カベルネ・ソーヴィニヨンはフランスのボルドーが原産ですが、ボルドーではカベルネ・ソーヴィニヨンは単独でワインを作るのではなく、メルローという品種と組み合わせることが圧倒的に多いです。
さて、これらを念頭においてデータモデルにしてみます。
中心となるデータはワインですので、まず、これをエンティティとします。「ワイン」エンティティのインスタンスですが、同じ名前のワインでも作り手、ヴィンテージが違うとものすごく値段が違うので、それごとにインスタンスを作成することにします。主キーは「ワインコード」としてみましたが、これだと粒度がわからないので、「ワイン名」+「ヴィンテージ(ブドウを収穫した年)」*「作り手コード」を代替キーとします。シャンパーニュは原則としてヴィンテージは入らないので、その場合はNV(ノン・ヴィンテージ)と設定することにします。
「ブドウ品種」エンティティの主キーは「ブドウ品種名」とします。インスタンスはカベルネ・ソービニヨン、メルロー、シャルドネ、ソービニヨン・ブランなど。いま、日本で売っているワインの大部分はここであげた4品種から作られたものですね。
ワインによっては複数のワイン品種から作られますので、データモデルでは、「ワイン」エンティティと「ブドウ品種」エンティティはn:nの関連があることになります。n:nを1:nにするために交差エンティティ(関連エンティティという呼び方もあります)をモデルに追加しましょう。ここでは「ワインブドウ品種」というエンティティ名とします。「ワインブドウ品種」エンティティの主キーは、「ワインコード」+「ブドウ品種コード」の複合キーとするのが普通かと思います。
交差エンティティによってn:nを2つの1:nに変換しましたが、この2つにはどのような違いがあるでしょう?
「ワイン」のインスタンスなしで、「ワインブドウ品種」のインスタンスはありえません。
一方、ブドウ品種はワインに向くものと生食に向くものがありますので、「ブドウ品種」のインスタンスをワインに使われるものに限定しない限り。「ワインブドウ品種」に対応しない「ブドウ品種」のインスタンスがあり得ます。こういったことは「ブドウ品種」エンティティに、その定義を書いておくことで明確になります。
そう考えると、2つの1:nの関連には違いが出てきます。
カーディナリティを厳密に書くと、1:1..nと1:0..nとなります。
サンプルに掲げたER図にはそれ以外の要素もあります。「地方」エンティティに再帰リレーションシップがあることや、格付が「地方」と「ワイン」の両方にあるところ、「ワイン分類」の「バランス分類コード」とは何を意味しているのかなど。これを発展させてワインの販売管理のモデルを考えてみるなどは次回のお楽しみにとっておきます。