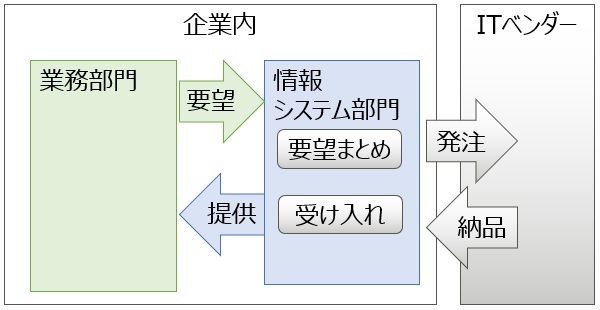
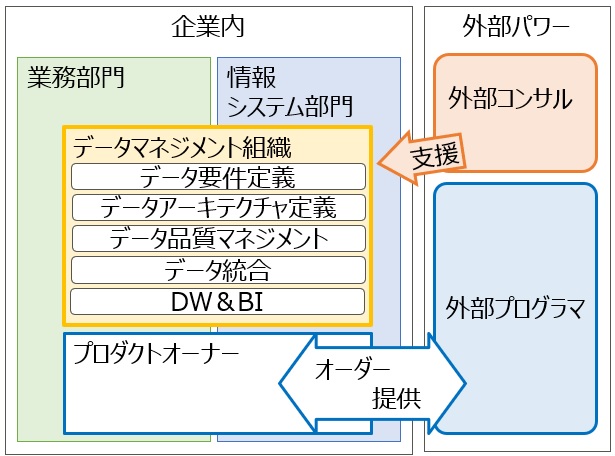
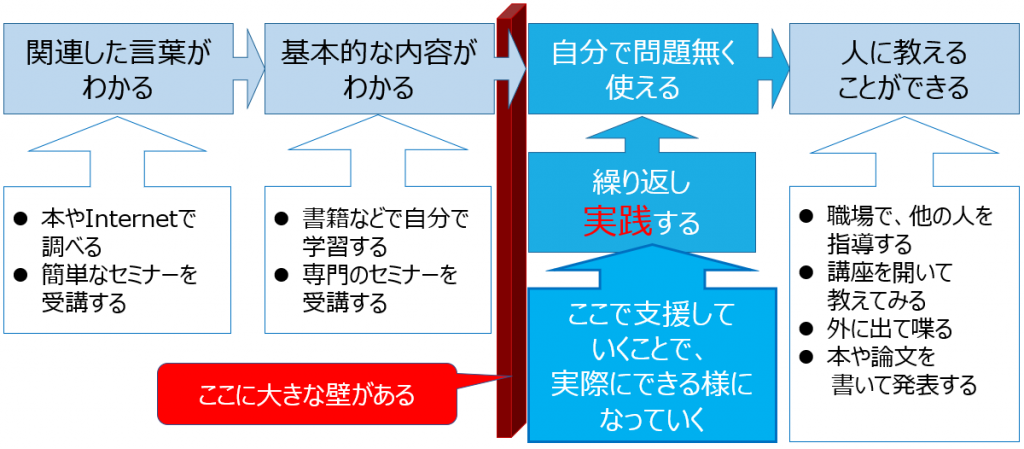
これまで、主に 主にデータモデリングについて取り上げてきましたが、今回は関係深いものの一つとして、データプロファイリングについて紹介したいと思います。以前にも、少し触れていますが、もう少し詳しく見てみましょう。
DMBOK2での記述
DMBOK2の中でも、 何箇所かで取り上げられているので見てみましょう。最も大きく取り上げているのは「第13章 データ品質」の中です。1.3節の本質的な概念の9番目に「1.3.9 データプロファイリング」として登場します。
定義としては「データを検査し、品質を評価するために行われるデータ分析の一形式である」とされています。統計的手法を活用して、収集したデータの真の構造、コンテンツ、品質を洗い出すとあり、データのコンテンツと構造のパターンを識別するために利用できる統計処理結果を生成します。
| NULL数 | NULLが存在することを検出し、許容可能かどうかを検査できるようにする。 |
| 最大値・最小値 | マイナス値などの異常値を検出する。 |
| 最大長・最小長 | 特定の桁数要件を持つフィールドの外れ値や異常値を検出する。 |
| 個々のコラムに存在する値の分布度数 | 値の妥当性を評価できるようにする。(トランザクション内の国コード分布、値の発生頻度検査、初期値が設定されているレコードの割合など)。 |
| データタイプとフォーマット | フォーマット要件への不適合レベル、想定外のフォーマット(小数点以下の桁数、スペースの混入、サンプル値など)を検出する。 |
この表に見られるのは、主に一つのテーブルの各項目ごとの分析となっていますが、この他にもテーブル内での書く項目間の関連や、テーブル間での関連を分析することがあり、DMBOK2ではクロスカラム分析と記載されています。
「第5章 データモデリングとデザイン」では、ツールの節で「3.3 データプロファイリングツール」として紹介され、ツールによってデータの中身を調べ、既存のメタデータと照らし合わせて検証したり、既存のデータ関連生成物の不備を特定したりするのに役立つことがかかれていました。例として、従業員に複数の職位がある場合をあげていました。
DMBOK2では、データプロファイリングが何らかの形で、第5、8、10、11、12、13、14、15、17の各章に登場しています。
ツールの利用に関して
データの中身の検証は、データプロファイリングという名前で紹介される以前から実施されてきました。私の場合、初期としてはシステムの再構築におけるデータ移行を目的として始めた記憶があります。特に最初に行ったのは、いわゆる「区分値」の調査でした。再構築に伴い「区分」も見直され、統合や新設、再編を行うことがありますが、その対応をマッピングするために、現在実際に使われてきた値を調べることを目的としていました。
このために、多くはレプリケーションのデータベースでSQLでGROUP
BY句を使って、区分値の種類と、実際に使われている数を出していました。
SELECT 区分値, COUNT(*) FROM 表 GROUP BY 区分値;
こんな感じで、必要な数のSQL文を実行していけばそれなりに機能しますが、テーブル数、項目数が多いと大変です。現在では、データ品質やデータカタログ関連のツールで、プロファイリングの機能が搭載され、簡単に正確に、度々検証することができるようになっています。
区分値だけでなく、コード系などでもXXX-XX-XXXとか、XX-99-9999などのようなものが混じって居たり、過去の経緯で色々と乱れているものも発見できたりします。
システム再構築の際のデータ移行だけに使うのではペイしないかも知れませんが、その後のデータ品質とガバナンスに繰り返し使うことを合わせて導入するのが良いかと思います。
データモデリングと関連して
データモデリングを行ったら、できればデータプロファイリングも実施して、区分値によるサブセットの検証を実施して欲しいです。ナンバーコードに埋め込まれた有意味のコードも確認できます。
データモデリングによってサブセット分析を行い、区分による業務の差異をサブセットとして切り出せますが、定義書にかかれている区分値と実際のデータベースに入っている区分値では実際には少し異なることがあります。 定義書によれば、1、2、3の値が定義されていても、実際には3は使用されておらず、一方で4とか5とか、場合によっては99みたいな値が勝手に作られていることが少なくないようです。
この場合、3に相当するサビセットは実際には不要で、4と5に関するものを詳細に調査する必要があります。また、99のような値が設定されている場合は、その値をプログラム中でどのように扱っているかまで、確認する必要がありそうです。
こういった議論も第10分科会で展開していこうかと思います。