IT組織、IT人材育成の中でのデータマネジメントの位置付けについて、今回は、記載したいと思います。
データマネジメントの活動は、DMBOK(データマネジメント知識体系ガイド)に定義されていますが、企業や事業活動の中で、データマネジメントがどこに位置付けられるのか、考えてみました。また、人材育成面で、データマネジメントについて、定義されているものがあるか考えてみました。
企業や事業活動の中で、当たり前のように、データマネジメントが位置付けられていれば、もっともっと、よりデータマネジメントが認知され、価値が上がり、育成にも力を入れ、みなさんがより活動しやすくなるのではと思っております。
今回は一例です。データマネジメントは、ITに関わる組織、人、のみに関係するのではなく、企業全体での事業活動・取組みがデータマネジメントと思いますので、ITに特化した話をすべきではないと思っていますが、まずは、IT組織・活動の一例を記載したいと思います。
「i コンピテンシ ディクショナリ」というものをご存知でしょうか。ご存知の方も多いと思いますが、紹介したいと思います。
「i コンピテンシ ディクショナリ」とは、IPA(独立行政法人 情報処理推進機構)のIT人材育成事業の取り組みの一つで、人材育成の枠組みになります。
IPAが提供する「i コンピテンシ ディクショナリ」(以降、iCD)は、企業において、
- ITを利活用するビジネスに求められる業務(タスク)
- それを支えるIT人材の能力や素養(スキル)
を「タスクディクショナリ」、「スキルディクショナリ」として体系化したものになります。
「タスクディクショナリ」、「スキルディクショナリ」、それぞれ辞書のように参照できる形で構成立ててまとめられており、「タスクディクショナリ」は、タスク3階層と評価項目の計4階層で構成。「スキルディクショナリ」はスキル3階層と知識項目の計4階層で構成されています。
実際に、IT組織(IT部門、SI会社、IT関連会社等)の新規立上げ時の組織や業務の定義、また、事業・業務運営中の際も、改革・改善検討、役割整理の参照モデルとして「タスクディクショナリ」が使われていたり、人材育成時のスキルの棚卸し、定義、また人材評価の仕組みを策定する上での参照モデルとして、「スキルディクショナリ」が使われており、企業は経営戦略などの目的に応じた人材育成に利用することができます。
2014年7月31日にいiCDの試用版を公開し、パブリックコメントや産業界における実証実験などを踏まえ、2015年6月に正式版を公開されています。
以下、参照下さい。
https://www.ipa.go.jp/jinzai/hrd/i_competency_dictionary/icd.html
iCD2018から新たに「タスクディクショナリ」に、「データマネジメント」のタスク追加がされました。
オレンジ色の線で四角に囲っている部分です。
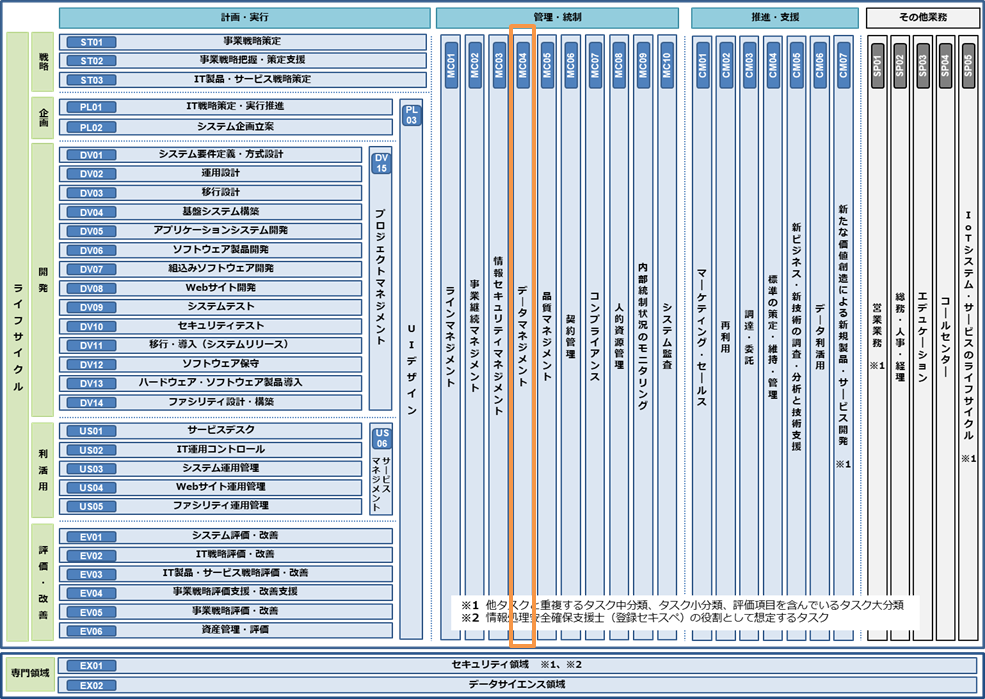
出典: iCD タスクディクショナリ タスク構成図 から引用。
iCDのタスクディクショナリの「データマネジメント」タスクには、以下が定義されています。
- データガバナンス
- データセキュリティ管理
- データ品質管理
iCDでは、上記の図の左の方には、戦略、企画、開発等のタスクが定義されていまずので、データマネジメントに関するタスクはその中にもあり、位置付けられています。(データ設計等)
当然、iCDと、皆さんが活用されているDMBOKは、別の目的で作られたものであり、カバーする範囲もカテゴライズも、異なりますが、 企業においてITを利活用するビジネスに求められる業務(タスク)の中で、データマネジメントが定義されているのか、また、どこに位置付けられているのか、参考にして頂ければと思います。
「スキルディクショナリ」には、スキル、職種が定義されており、データマネジメントに関するスキル、職種も探して頂ければ、参考になると思います。
iCDは、以下、オフィシャルサイトもありますのでご参考までに。
https://icd.ipa.go.jp/icd/
「タスクディクショナリ」、「スキルディクショナリ」 は上記サイトからダウンロード可能です。
以上