DMBOKの厚さをどう攻略して読むか
DMBOK第二版日本語版が出版されてから、4年以上が経過しました。
この間、DXに伴うデータ利活用ニーズの高まりと共に増刷を続けています。
SNSなどの反応を見ていると、当初の読者層はコンサルタントやSIer企業の方が多かったものの、最近ではユーザ企業の方からも多くの反響をいただいています。翻訳に関わったものとしてうれしく思っています。
ただ、はじめてデータマネジメントを学ぼうという方からは、
「650ページを超える書籍を全て読みきるのは大変。効率良い読み方はありませんか?」
と相談されることも増えてきました。
相談される方から伺ってみると、「効率良い読み方」として期待されているのは、
・すでにデータマネジメントに関わる課題を抱えている方が、解決策を早く知る方法
・データマネジメント全体を知識として学びたい方が、より深く理解しやすい方法
の大きく2つに分かれるようです。
前者については、本ブログ以外にも参考となる記事が他サイトにあります。
『DMBoK2の歩き方とデータガバナンスの位置付けを考える』
https://dama.data-gene.com/tag/dm-walking-map/
『全672ページの超大作、データマネジメント知識体系ガイド「DMBOK2」の攻略法』
https://japan-dmc.org/?p=19468
『日本語版DMBOK2を読む』 https://metafind.jp/2018/12/10/reading_dmbok2_in_japanese/
以下では、後者の視点について掘り下げて、いわばDMBOKを知識教養として学ぶための読み方のポイントをご紹介します。
章をまたいで用語や概念が解説されていてわかりづらい
DMBOKの、たとえば参照データとマスターデータのような特定の章について読んでいると、メタデータやデータ品質、データガバナンス等の他の章に関わる説明が出てきます。
DMBOKをデータマネジメントの「教科書」として読みたい方は、まずここで立ち止まってしまうようです。歴史の教科書であれば、まず古代から中世、近代と章毎に理解でき、先行章の理解が後続章の理解をより深めてくれますね。
しかしDMBOKはそのような作りではありません。(仮に歴史の教科書をDMBOK式に書き変えるならば、「歴史とは」という章ではじまり、「哲学宗教」「政治統治の方法」「共同体の形態」といった章構成になりそうです。)
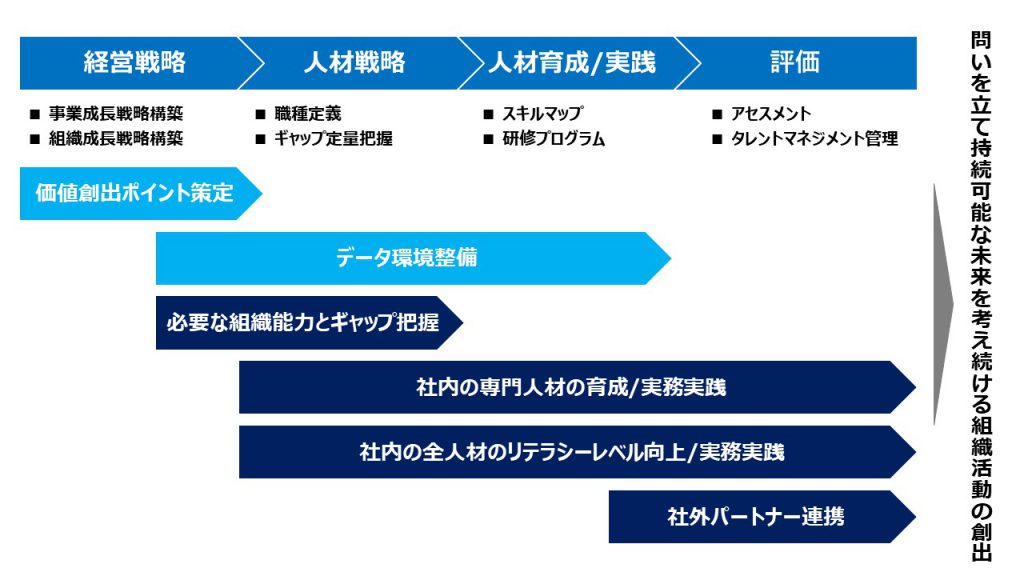
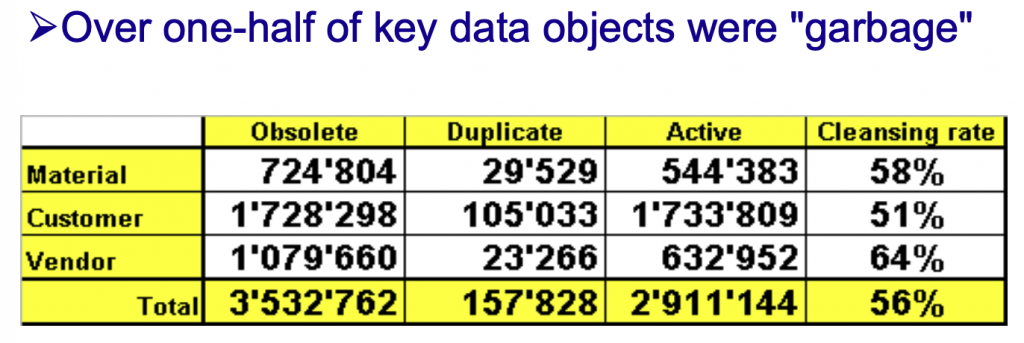
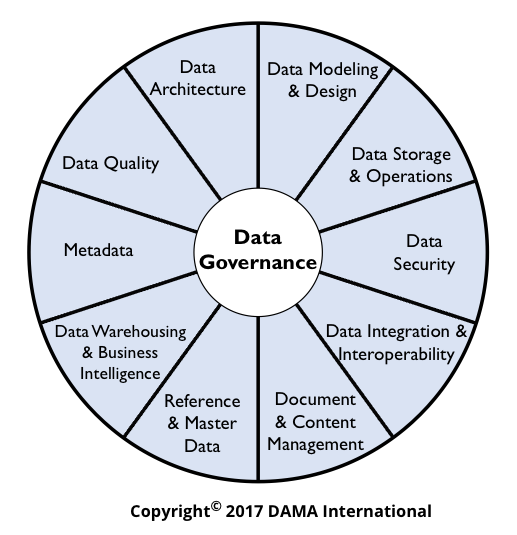 DAMAホイール図(各セクションが主要11章に対応)
DAMAホイール図(各セクションが主要11章に対応)
DMBOKは主要11章を「知識領域」と呼んでいます。この領域というものはデータマネジメントに関する知識を①データの種類②性質③管理手段の違い※でまとめた単位です。(※たとえばそれぞれ代表的な章として①参照データとマスターデータ、②データ品質、③データモデリングとデザインが挙げられます。)
データ品質と一言で言っても、メタデータやマスターデータの品質もあればそのどちらにも該当しない品質もあります。これらはみな、DMBOKでは別々の章に書かれています。そのため、「DMBOKでデータ品質に関わる知識を深めたい」という方は、いずれは650ページすべてを読まなくてはと考えがちです。
とは言え、650ページ全て読み込むのはハードルが高いというのが今回の主旨でした。
最初は章単位ではなく”節”単位で読み込むのがオススメ
DMBOK第二版の第3章から第15章までの各章は、どの章もほぼ以下の構成です。
第1節 イントロダクション
1.1. ビジネス上の意義
1.2. ゴールと原則
1.3. 本質的な概念
第2節 アクティビティ
第3節以降 ツール、技法、導入ガイドライン、ガバナンス、文献 等
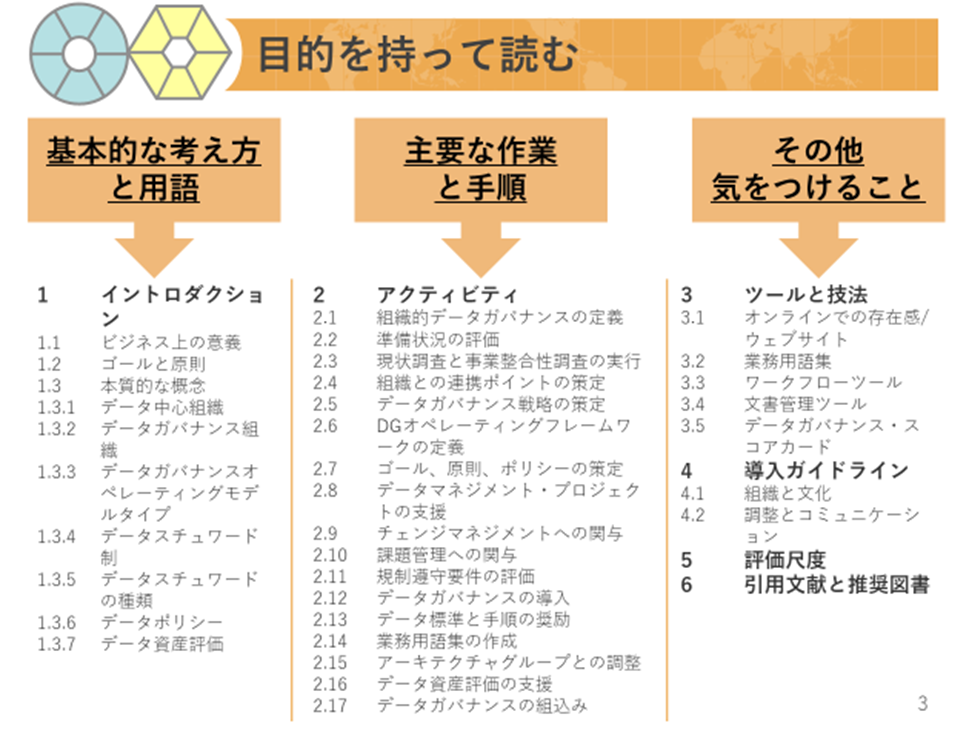 第3章 データガバナンスの目次
第3章 データガバナンスの目次第1節は、その知識領域の基本的な用語と考え方を紹介しています。
第2節は、その領域で一般的に実施される活動と手順が解説されます。
第3節以降は、DMBOK第二版英語原本が書かれた2015年時点で、その領域について広く普及していたツールや技法、ガバナンス方法が書かれています。
英語原本が書かれてからすでに7年が経過しているため、現在からすると第3節以降の内容に古さを感じるものもあります。
一方で、第1&2節の内容は、具体的なツールや方法論ではなくコンセプトを書いているため、これからも参考になります。
全くはじめてデータマネジメントに触れるという方は、まずは第3~15章の用語の解説を読み通すと良いでしょう。そうすれば、各章に分かれて記述されている知識が、頭の中で紐づくはずです。
ひととおり用語についての知識が身についた方は、次に、章を横断して第2節を読むことをおすすめします。第3節以降の知識を前提には書かれていないので、第2節を繰り返し読むだけでも具体的な活動内容について理解できるはずです。
ちなみに、第1/2/16/17章は、知識領域横断で考慮するべき内容が記述されています。
- 第1章:第3~13章全体を通した、データマネジメント全体の目的と原則
- 第2章:データを取り扱う際のリテラシー
- 第16&17章:データマネジメントを成功させるための組織文化
これらは他の章に比べてより抽象的な記述が多いので、最後にまとめて読むと良いのではないでしょうか。
まとめ
DMBOKを購入したものの、その厚さと難解さに心が折れて「積読(つんどく)」していませんか?
また、DMBOK以外の、ほどほどの厚みで読みやすい本でデータマネジメントを学んだものの、物足りなさを感じていらっしゃいませんか?
そうした方はぜひ、章を横断して第1節の基本的な用語の解説を読んでみてください。第1節だけ読み返すなら、それほどボリュームはありません。
もう少し踏み込んで、どんな活動をするのか学びたい方は、第2節を読み進めてください。
そして次のステップとして、DMBOKの基礎用語や活動の解説を参考に、みなさんの所属する組織やお客様に対して、DMBOKをベースにデータマネジメントを実践してはいかがでしょうか。