小規模なシステムで,単独で稼働するようなものであればデータモデルはDB設計の前段と捉えてもそれほど問題にならないが,企業や政府のシステムは複雑で,多数のシステムから構成されているため,全体を見通すことが難しい。企業合併や買収もあると,システムがそこかしこで分断され,無理やりのデータ変換や,EXCEL等の利用も含めた人間系を介在させることで,なんとかやりくりしていることも多い。
また,多数のシステムのうちのいくつかは外部から購入したパッケージやクラウドサービスを利用しているのも普通であろう。これらは内部のデータ構造はブラックボックスであることも多く,当該組織に合わせて最適なデータモデルというわけにはいかないことも多いだろう。しかし,全て自前のカスタムシステムで組織全体のシステムを構築することは時間的にも,コストの面でも現実的ではない。いや,時間をかけてもビジネスの変化についていけないシステムを長期間かけて構築することになりかねず,出来上がったときは,既に陳腐化している恐れもある。パッケージやクラウドサービスを組み合わせて使うことを前提として考えるべきだろう。
では,その前提に立ち、システム群を全体最適な構造に再構成し、どう維持していくかという課題に対する答えが、システム群を横断するエンタープライズレベルのデータモデルである。注意してほしいのは、個々のシステム内に閉じているローカルなデータは対象とせず、システム間で共有、連携されるグローバルなデータにフォーカスすることである。
データモデルとDB設計は密接な関係があるが(混同されている場合も多い),パッケージやクラウドサービス,継続使用可能なレガシーシステムを活かしつつ,アドホックでなく,アーキテクチャとしての連携を成功させる鍵は、システム群を横断するデータモデルである。DB設計のスコープは個々のシステムだが,エンタープライズレベルにスコープを広げたデータモデルが必要とされているのである。ただし、DB設計だけに引き継がれるのではなく、連携データのフォーマットやメタデータ定義、コード定義につながるのである。
DMBOK2では,DMBOK1にはなかった幾つかの章があるが,その1つとして「第8章 データ統合と相互運用性」がある。ここでは直接、データモデルに言及しておらず、テクニカルなデータ連携アーキテクチャに関する記述がメインだが、それだけではデータ統合はできない。 データHUB,EAI,ESB等が取り上げられているが,こうしたテクニカルなプラットフォームだけでは,個々のパーツ(システムやサービス)を全体最適の観点でつなぎあわせることはできない。
データモデルの適用スコープをここまで広げ,複数のシステムが会話する共通語としてデータモデルとメタデータ定義を行い,それに基づいて,個々のシステムが会話,連携できるようにすることがポイントである。アイテムや顧客についてはエンタープライズレベルのデータモデルに合わせてることで、複数のシステムが無理なく連携可能となる。
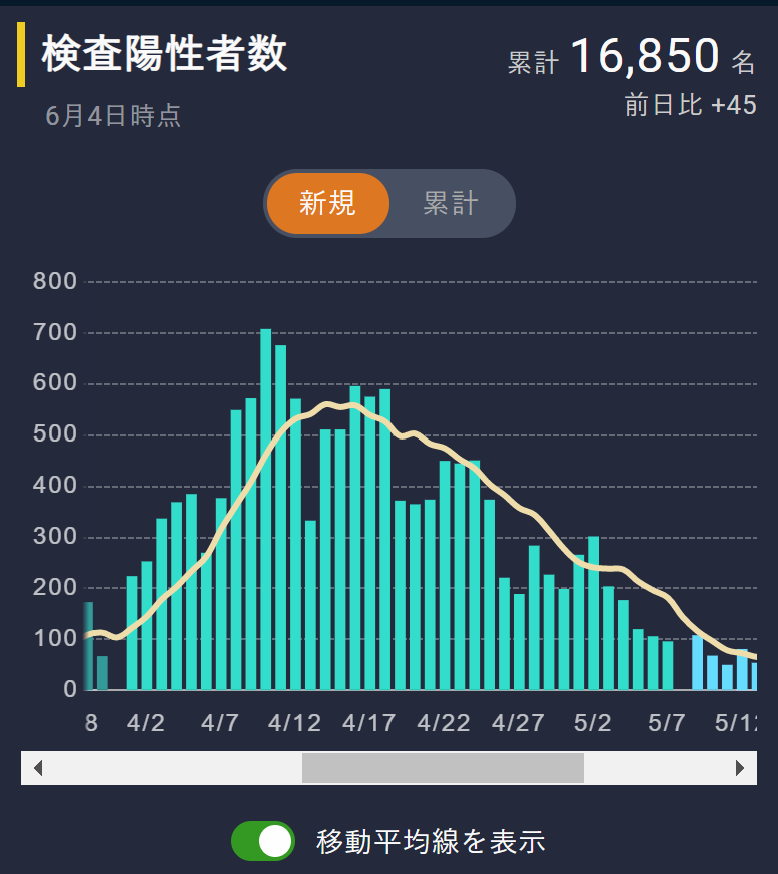
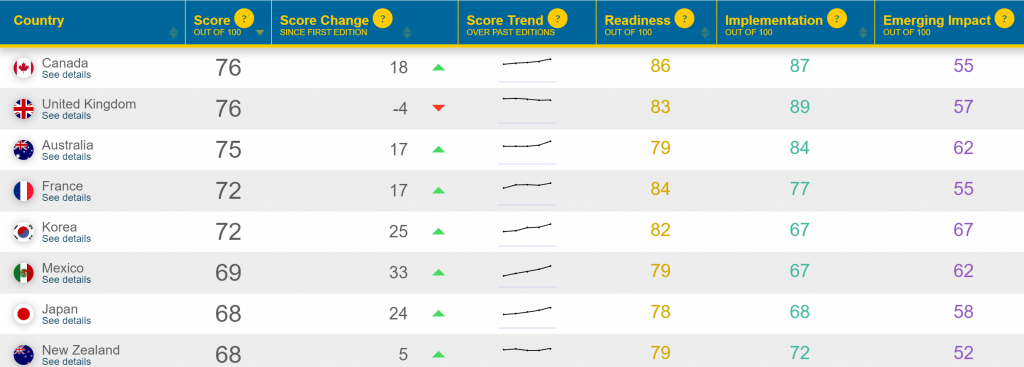
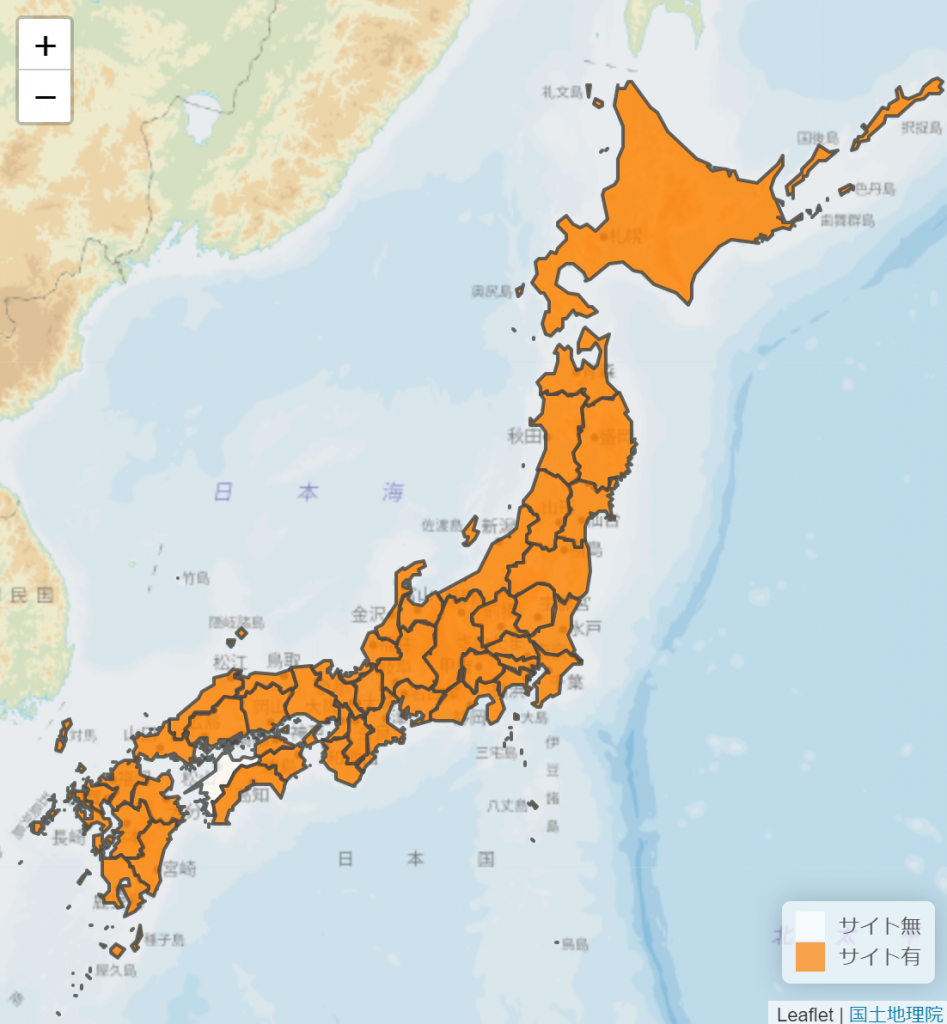
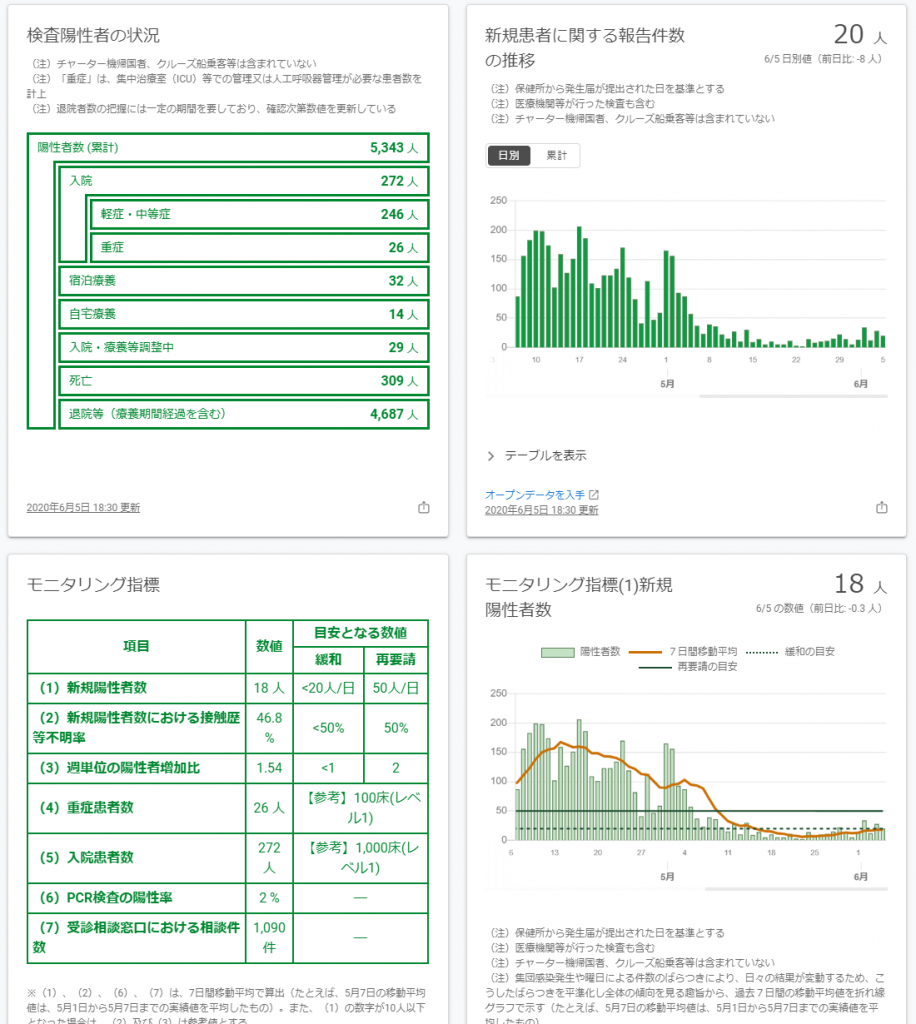
種々の事情があり,制約も多いため,安易な批判は避けたいが,特別給付金の電子受付と個々の自治体のシステムがうまく連携できなかったのも,こうした複数システムのスコープでモデルを作成できなかったことも関係しているのではないかとも思えるのである。