前回の私のブログ「標準の作成と定着化について」では、会社や組織にデータマネジメント等を推進、定着化させるための一つの手段として、その専門領域の知識体系(BOK)(データマネジメント知識体系ガイド(DAMA―DMBOK)等)を活用した標準化、定着化の考え方、進め方の概要を記載しました。
その際には、多くの会社で、会社・組織の標準として規定されており、データマネジメントと「マネジメント」部分の名前が同じ、プロジェクトマネジメントの標準化を例として、考え方や、進め方を記載しました。
今回は、その具体的な進め方の例を記載します。
進め方として、大きく、以下の3つのステップに分かれます。
<進め方>

- ステップ1:標準文書作成
- ステップ2:試行実施(個別案件への適用にて試行)
- ステップ3:全社本格展開
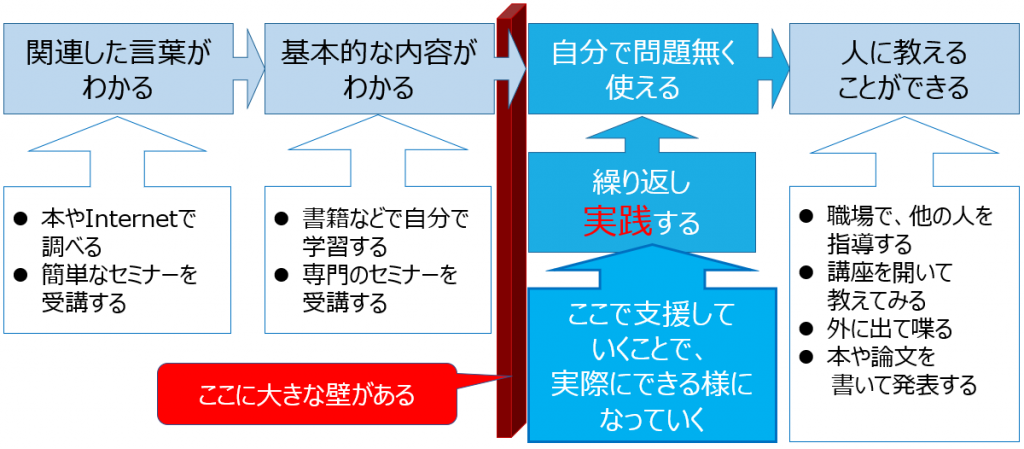
ここで重要な事は、標準文書を作成しただけで満足せず、 標準文書を作成 した後の、会社、現場でより定着するための取組みが大変重要になります。 標準文書を作成しただけで、みんなが活用してくれない、存在さえ知らない人が多い・・・・と嘆いておられる方もいるのではないでしょうか。 その場合は、標準文書作成時での経営層、現場の方の巻き込み、作成後のアフターフォローが不十分な事が原因と思われます。標準化についても、通常の業務、プロジェクトと同様、上記のステップの全体を網羅した計画をきちんと立て、計画通りに実施し、運用後も引き続き、ウォッチ、支援、活動していくような仕組み作りが大変重要になります。
実際に進めていくには、ステップ毎に詳細なタスクがあり、その詳細タスク毎に進める事になります。
ステップ毎の詳細タスクの例は、以下のようになります。
<ステップ1:標準文書作成>
- 標準化チーム立上げ
- 現状分析(課題の洗い出し・整理、対策立案)
- 標準文書作成、レビュー
- 標準文書完成
<ステップ2:試行実施(特定案件への適用にて試行)>
- 個別案件への適用計画作成
- 試行実施(個別案件への適用実施)
- 個別案件適用結果の評価とフィードバック(標準文書ブラッシュアップ)
<フェーズ3:全社本格展開>
- 全社への適用計画作成
- 本格適用アナウンス
- 現場への標準文書説明会実施
- 本格適用
- 定期的な標準文書の教育計画作成・教育実施
- 現場適用支援
- 本格適用結果の評価とフィードバック(標準文書ブラッシュアップ)
※継続的な改善(プロセス改善・標準文書改善・・・PDCAサイクル)
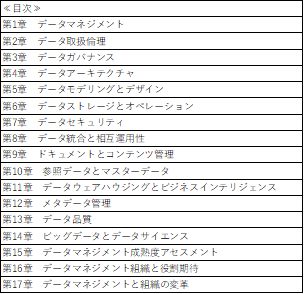
そもそも標準文書はどのような目次構成なのでしょうか・・・。
DAMA―DMBOKは、以下の目次になりますね。
簡単ですが、標準文書の目次構成の例を、以下に記載します。
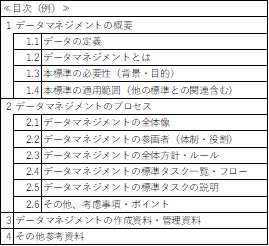
上記はあくまで例ですので、会社、組織に合わせて、必要な目次、構成、順番等、決めていく必要があります。上記の例では、本取組みを行う、背景や目的、今回作成した標準文書の必要性、対象となる適用範囲、本標準を進めていく上での参画者・役割をきちんと定義することで、よりマネジメントの実施と本標準の活用につながります。
次回は、標準化における、計画時や標準文書作成時、適用・運用時のポイント・コツを記載できればと思います。
以上